
I’m going to teach you how to create a program that can beat you at video games. In 10 minutes or less. Go!
Reinforcement Learning (RL) is one approach to creating Artificial Intelligence by teaching a computer (or “agent”) to do something without telling it how explicitly. The basic idea involves the agent playing around within its environment. When the agent makes an action, something happens and it is given some reward value. The goal is to train the agent to maximize the reward value. Reinforcement Learning is particularly interesting because it has the ability to generalize well to new tasks and environments.
This is actually similar to the way that humans learn: we first take action - if the action does something good, we are rewarded. Over time, we learn to associate certain actions to better outcomes. The process, known as a Markov Decision Process, is shown below.
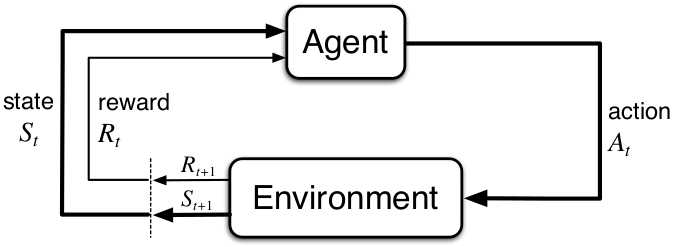
The agent starts in its current state. It makes an action. As a result, the environment changes. The state is updated and a reward value is returned to the agent. This cycle then repeats itself until the environment is solved or terminated.
For a video game, the environment is the world of the game and the rules that govern it. The state is an array of numbers representing everything about how the game world looks at one specific moment.
Let’s look at the classic game “Cart Pole”, in which the player tries to balance a falling pole on a moving cart.
The game laws work like this:
A pole is attached by a joint to a cart, which moves along a frictionless track. The system is controlled by applying a force of +1 or -1 to the cart. The pole starts upright, and the goal is to prevent it from falling over. A reward of +1 is provided for every time step that the pole remains upright. The episode ends when the pole is more than 15 degrees from vertical, or the cart moves more than 2.4 units from the centre.
The entire state of this simple game can be described with 4 numbers: the cart position, the cart velocity, the angle of the pole, and the angular velocity of the pole. Our machine’s goal is to create a policy which decides what action to take depending on the current state.

A policy is a mapping that takes the current game state as its input and returns the action the agent should take (e.g. move the cart right or left). This cycle continues with the updated state from the chosen action, which is provided to the policy again to make the next decision. The policy is what we’re trying to fine-tune and represents the agent’s decision making intelligence.
In the context of Cart Pole, the policy is an array of weights which determines how important each of the 4 state components is to taking a specific action. We multiply each weight by the state components, then sum them all to come up with a single number. This number represents the action that we will take. For Cart Pole, if the number is positive, we move the cart to the right and vice versa.
Now that we understand the concept, let’s try to build an agent to beat the game.
Our first step is to import the libraries we need to run a Cart Pole game in an OpenAI Gym environment (software library developed to simulate and test RL algorithms). We will also import numpy, a helpful mathematical computing library.
import gym
import numpy as npNext, we’ll create the environment.
env = gym.make('CartPole-v1')In order to run through episodes, let’s build a function that accepts the environment and a policy array as inputs. The function will play the game and return the score from an episode as output. We’ll also receive an observation of the game state after every action.
def play(env, policy):
observation = env.reset()
# create variables to track game status, score, and hold observations at each time step
score = 0
observations = [ ]
completed = False
# play the game until it is done
for i in range(3000):
# record observations
observations += [observation.tolist()]
if completed:
break
# use the policy to decide on an action
result = np.dot(policy, observation)
if result > 0:
action = 1
else:
action = 0
# take a step using the action (the env.step method returns a snapshot of the environment after the action is taken, the reward from that action, whether the episode is completed, and diagnostic data for debugging)
observation, reward, completed, data = env.step(action)
# record cumulative score
score += reward
# end the function by returning the cumulative score and full list of observations at each time step
return score, observationsAwesome! Now that our brave agent is able to play the game, let’s give it a policy to do so. In the absence of a clever strategy for devising a policy, we’ll start with random values centred around zero.
policy = np.random.rand(1,4) - 0.5
score, observations = play(env, policy)
print('Score:', score)After running the script, how did our agent perform? Cart Pole has a maximum score of 500. In all likelihood, our agent yielded a very low score. A better strategy might be to generate lots of random policies and keep the one with the highest score. The approach is to use a variable that progressively retains the policy, observations, and score of the best-performing game so far.
# create a tuple to hold the best score, observations, and policy
best = (0, [], [])
# generate 1000 random policies centred around 0 and keep the best performing one
for _ in range(1000):
policy = np.random.rand(1,4) - 0.5
score, observations = play(env, policy)
if score > best[0]:
best = (score, observations, policy)
print('Best score:', best[0])Chances are, we have come up with a policy that is able to achieve the high score of 500. Our agent has beat the game!
Where do we go from here? You may have realized something important - the policy we ended up with wasn't learned! It was selected by an iterative approach. If we wanted to build a better system that is more worthy of the AI title, we might consider some of the following approaches:
- Using an optimization algorithm to find the best policy instead of iteratively selecting (e.g. Deep Q Learning, Proximal Policy Optimization, Monte Carlo Tree Search, etc.)
- Testing the best policy that we obtained over many episodes to ensure that we didn’t just get lucky in the one episode
- Testing our policy on a version of cart pole with a higher top score than 500 to see how sustainable the policy is
Thank you for reading.